Many-to-Many Relationship in MongoDB
Model Intricate Data
“In the affair of human race, it is bad to have many relationships. In computer science, however, it is good.”
I recently added tags to blog posts. This blog-tag relation is a classic many-to-many relationship model. MongoDB documentation writes only of how to model one-to-many relationship. So, I am going to show you how I modeled many-to-many relationship in MongoDB, in which the data of this website is stored.
Prerequisites
I assume that you have MongoDB installed on your computer, and have basic knowledge of NoSQL.
As of this writing, my MongoDB is version 5.0.4. I believe the version 3.0 upwards works well with the all commands shown below.
If you haven’t yet installed MongoDB, please refer to their installation guideline.
Model
The idea of blog-tag relationship is depicted as below:
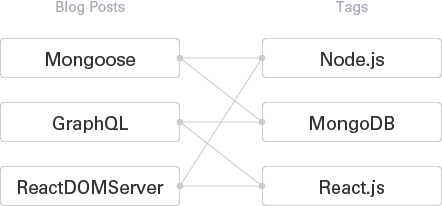
The models below are not exactly how my database is modeled. It is rather just to show you as a guideline.
Blog
{
id: Integer,
title: String,
tags: Array of Tag ID
}Tag
{
id: Integer,
name: String,
}I added the field id so that the readers can copy, paste and run the same queries. But in practical application, the ObjectId _id assigned to every document will do—in fact it is preferred.
Normalized v.s. Embedded
In the model above, I adopted the normalized data model, also known as referential model. In normalized data model, documents store references to the other documents, which are used to link two documents. Usually the ObjectId of document is used as a reference.

The other way of modeling is the embedded data model. In this model, the relationships of data are store as a sub-document inside a single document.

Generally speaking, in one-to-many or many-to-many relationships the normalized data model is preferable since it can save the amount of data, and a change on the referenced document updates all data related referencing documents. Even for one-to-one relationship in which the link between two documents is so weak or so delicate—like credit card information for users—you can use the normalized data model.
Seed Data
As an example, I will use database named m2m, stands for many-to-many, and two collections blogs and tags. To store seed data to database, boot up your MongoDB and log in to its shell:
% brew services start mongodb-community # on version 5
% mongoshAnd create three documents for each collection with insertMany():
> use m2m
> db.tags.insertMany([
{id: 0, name: 'Node.js'},
{id: 1, name: 'MongoDB'},
{id: 2, name: 'React.js'}
])
> db.blogs.insertMany([
{id: 0, title: 'Mongoose', tags: [0, 1]},
{id: 1, title: 'GraphQL', tags: [1, 2]},
{id: 2, title: 'ReactDOMServer', tags: [0, 2]}
])Please make sure those data are stored with db.collection.find():
> db.tags.find()
// Output
[
{_id: ObjectId("62…bd"), id: 0, name: 'Node.js'},
{_id: ObjectId("62…be"), id: 1, name: 'MongoDB'},
{_id: ObjectId("62…bf"), id: 2, name: 'React.js'}
]
> db.blogs.find()
// Output
[
{_id: ObjectId("62…c0"), id: 0, title: 'Mongoose', tags: [0, 1]},
{_id: ObjectId("62…c1"), id: 1, title: 'GraphQL', tags: [1, 2]},
{_id: ObjectId("62…c2"), id: 2, title: 'ReactDOMServer', tags: [0, 2]}
]From now on in this post, I will eliminate _id field from the outputs.
Queries
To compute documents through multiple processes, we use Aggregate Operations in MongoDB.
We used db.collection.find() in the above, and this function accepts three arguments query, projection, and cursor methods.
- query: determines the filter which documents are to be returned.
- projection: determines which fields are returned in the matching documents.
- cursor methods: determines optional computation such as sort, limit, skip.
Please try one query:
> db.blogs.find({tags: 1}, {_id: 0}, {sort: {id: -1}, skip: 1, limit: 1});
// Output
[
{id: 0, title: 'Mongoose', tags: [0, 1]}
]This is a simple query, so it shouldn’t be a problem. But when query gets complicated, it will. And some queries—like connecting blog post data with tag data—are impossible. The find() method above can be rewritten with db.collection.aggregate() as:
> db.blogs.aggregate([
{$match: {tags: 1}},
{$project: {_id: 0}},
{$sort: {id: -1}},
{$skip: 1},
{$limit: 1}
])
// Output
[
{id: 0, title: 'Mongoose', tags: [0, 1]}
]Join with $lookup
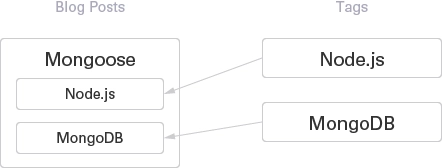
In relational database SQL, we use a JOIN to interrelate two tables. In MongoDB we use $lookup to do get the similar result.
Now let’s try one simple $lookup:
> db.blogs.aggregate([
{$lookup: {from: 'tags', localField: 'tags', foreignField: 'id', as: 'tags'}},
])
// Output
[
{
id: 0,
title: 'Mongoose',
tags: [{id: 0, name: 'Node.js'}, {id: 1, name: 'MongoDB'}]
},
{
id: 1,
title: 'GraphQL',
tags: [{id: 1, name: 'MongoDB'}, {id: 2, name: 'React.js'}]
},
{
id: 2,
title: 'ReactDOMServer',
tags: [{id: 0, name: 'Node.js'}, {id: 2, name: 'React.js'}]
}
]The IDs of tags in the blog document are replaced with tag documents.
The above $lookup is a bit tricky one. When localField is an array, you can join documents against a scalar foreignField. For the detail please refer to Use $lookup with an Array.
Filter by Tag
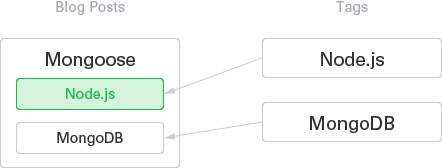
OK, we understood the basic of $lookup. Next, we want to find only blog posts tagged Node.js.
> db.blogs.aggregate([
{$match: {tags: 0}},
{$lookup: {from: 'tags', localField: 'tags', foreignField: 'id', as: 'tags'}}
])
// Output
[
{
id: 0,
title: 'Mongoose',
tags: [{id: 0, name: 'Node.js'}, {id: 1, name: 'MongoDB'}]
},
{
id: 2,
title: 'ReactDOMServer',
tags: [{id: 0, name: 'Node.js'}, {id: 2, name: 'React.js'}]
}
]See that we only get the blog posts that are tagged Node.js(id: 0), and the blog post GraphQL is filtered out.
$lookup Pipeline
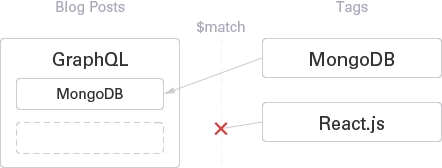
Now imagine a situation in which you don’t want to show people certain tags, be it currently under test. Let’s say that you are new to React.js. Although you tag the posts with that tag, you don’t yet want to show it in the query results. To do this, we pass pipeline at $lookup stage.
The query below is how you do it:
> db.blogs.aggregate([
{$lookup: {
from: 'tags',
localField: 'tags',
foreignField: 'id',
as: 'tags',
pipeline: [
{$match: {name: {$ne: 'React.js'}}}
]
}}
])
// Output
[
{
id: 0,
title: 'Mongoose',
tags: [{id: 0, name: 'Node.js'}, {id: 1, name: 'MongoDB'}]
},
{
id: 1,
title: 'GraphQL',
tags: [{id: 1, name: 'MongoDB'}]
},
{
id: 2,
title: 'ReactDOMServer',
tags: [{id: 0, name: 'Node.js'}]
}
]React.js is removed from the tag list joined to the documents.
Count Post Tagged
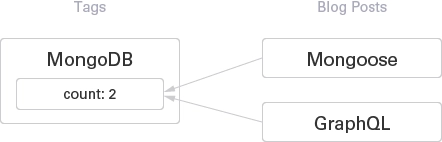
The great example of which you want to show the number of posts tagged the certain keyword is Tags of this website.
In the examples above, the queries are based in blogs, but this time it shall be based in tag. We add $project after $lookup, and to count the number of posts matched to the tag, we use $size operator.
> db.tags.aggregate([
{$lookup: {from: 'blogs', localField: 'id', foreignField: 'tags', as: 'posts'}},
{$project: {id: 1, name: 1, count: {$size: '$posts'}}},
])
// Output
[
{id: 0, name: 'Node.js', count: 2},
{id: 1, name: 'MongoDB', count: 2},
{id: 2, name: 'React.js', count: 2}
]Conclusion
To make many-to-may relationship in a relational database, we have to make a intermediary table like blog_tag that stores blog ID and tag ID in the rows. In MongoDB, which is a document-oriented database, that is unnecessary.
“Would there be any case that we won’t perform queries in MongoDB that we used to do in MySQL?” I cannot answer that question, honestly. “Which one is better, MongoDB or MySQL?” I cannot answer that question either.
We wish that there could be one-fits-all solution, but every thing is trade-off in development and engineering. The best solution depends on how we model data, in other words, on us, rather than on technology.
The exemplary queries shown above, and many-to-many modeling I adopted, is just one way of approaches. You could come up with the better idea.
And to get most of MongoDB, we shall get used to it, rather than to understand it.